Een zwaar beroepsgedeformeerd bedenksel dat Unicode* gebruikt om mededelingen compacter te maken door ze op te hakken in lettergroepjes en die om te zetten naar enkele Unicodekarakters. Zo wordt Drabkikker bijvoorbeeld:
dra | bki | kke | r
ቁ३ⵥɀ
* Voor wie nu glazig naar de einder staart: Unicode is een internationale standaard die alle ter wereld bestaande letters, karakters, leestekens, emoji’s en noem maar op van een uniek label voorziet. De p heeft label 0070, de ტ heeft label 10E2, bij de ⟱ hoort 27F1, een 📌 is 1F4CC, enzovoort. De labels gebruiken hexadecimale notatie want dat vinden computers fijn, vandaar die C’s en E’s en F’s ertussen, maar het zijn gewoon getallen. Je kunt ze ook naar decimaal converteren als je dat liever hebt: ‘1F4CC’ in hex is hetzelfde als ‘128204’ in dec.
Omzettabel
Wat je voor dat omzetten moet doen komt in essentie neer op het bouwen van een Exceltabel:
- Neem het ‘alfabet’ (plus een paar leestekens en een opvulnul – ik leg verderop uit wat die doet)
0abcdefghijklmnopqrstuvwxyz_.,?!, en maak een kolom met alle combinaties-van-drie daarvan, oplopend geordend van000,00a,00b… t/m …!!,,!!?,!!!. - Zet er een kolom naast met decimale getallen oplopend vanaf 0, 1, 2, 3 etc.
- Maak een derde kolom die de Excelformule
=UNICHAR()op die getallen loslaat. Dat transformeert de getallen naar hun corresponderende Unicodetekens. - Wie er graag ook nog de hexadecimale Unicodelabels bij wil hebben make een vierde kolom die de formule
=DEX2HEX()loslaat op de kolom met decimale getallen. Niet nodig, wel extra nerdpunten.
Als uw systeemtaal Nederlands is heten de formules =UNITEKEN() respectievelijk =DEC.N.HEX(). Wie heeft bedacht dat Excelformules er per taal anders uit moeten zien verdient een stevig onderhoud. Maar vooruit, dat het programma überhaupt instantformules blijkt te hebben die “help Drabkikker aan Unicodekarakters zodat hij niet per hexacimaal label handmatig in Word hoeft gaan lopen te Alt-X’en” betekenen maakt veel goed.

Een boodschap omzetten
Wat je nu hebt is een omzettabel waarin je in de lettergroepjeskolom (roze) kunt zoeken naar lettergroepjes en in de Unicodetekenskolom (blauw) naar de corresponderende Unicodetekens. De dec- en hex-kolommen heb je niet specifiek nodig, maar ze kunnen steun bieden.
Een boodschap omzetten gaat dan als volgt:
- Hak je boodschap op in groepjes van één, twee of drie letters (hoe meer drielettergroepjes, hoe compacter je Unicodecoderesultaat wordt): pan | tof | fe | ldi | ert | je
- Zoek in de omzettabel in de roze kolom naar die lettergroepjes en noteer de bijbehorende Unicodetekens in de blauwe kolom.
Opgelet: voor groepjes van één of twee letters wordt de opvulnul ingezet (om te zorgen dat alle lettergroepjes in de lijst uit drie tekens bestaan, dat ordent ordelijker). Voor éénlettergroepje q heb je bijvoorbeeld (in theorie – zie Moeilijkheden verderop) de opties00q,0q0enq00; voor tweelettergroepje fe kun je kiezen uit0fe,f0eenfe0; etcetera.
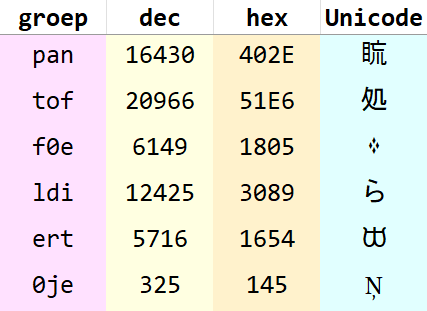
En zo heeft men pantoffeldiertje verUnicodecodificeerd tot 䀮処᠅らŅ.
- Spaties (in de tabel weergegeven met
_) en leestekens* worden op dezelfde manier verhakseld:
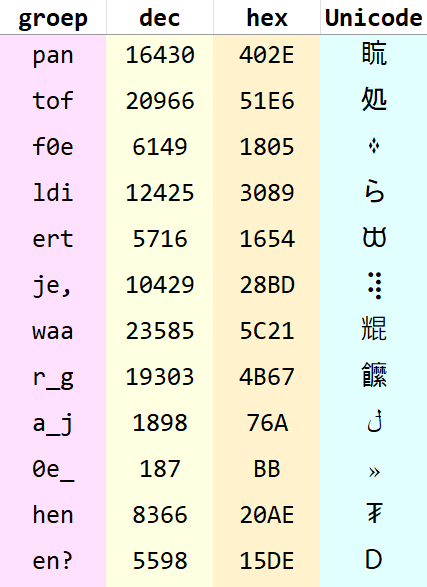
* Er zijn in mijn alfabet maar vier leestekens; mocht u er meer willen kunt u ze creatief combineren, bijvoorbeeld door af te spreken dat .. staat voor een dubbele punt, ., voor een puntkomma e.d. Voor cijfers is vast ook wel iets leuks te bedenken.
Moeilijkheden
En da’s het principe!
Nu doet Unicode in de praktijk op sommige fronten een beetje lastig. Bijvoorbeeld door voor sommige labels (nog) geen bijbehorend letterteken te hebben, dus dan kun je ze ook niet omzetten. Zo hebben de eerste 32 Unicodelabels überhaupt geen textuele betekenis (maar staan voor enigmatische dingen als ‘synchronous idle’) en hoort bij lettergroepje fel het label 18AC, maar dat is <reserved>, vandaar dat ik bij pantoffeldiertje hierboven alternatief heb moeten hakken en voor tweelettergroepje f0e heb gekozen want dat heeft wél een bruikbaar Unicodeteken (0fe en fe0 trouwens ook, dus die had ik ook kunnen kiezen).
Een andere uitdaging zijn combining characters: Unicodetekens die niet op zichzelf kunnen staan maar aan/op/in een voorgaand teken worden geplaatst: denk aan accenten en cedilles en pseudo-samvruthokarams. Als zo’n combinerend teken in Unicodecode opduikt moet je er soms een smokkelspatie voor of na invoegen om het juist weer te geven. Maar de spatie staat eigenlijk al voor lettergroepje 0a0, dus dan moet je wel afspreken dat je dat groepje niet gebruikt om de losse a mee weer te geven (maar in plaats daarvan a00 gebruiken; 00a hoort bij een non-textueel Unicodeteken dus die kan ook niet).
En dan heb je nog de mogelijkheid dat een Unicodelabel wel keurig een bijbehorend teken heeft, maar dat uw computer/telefoon het lettertype niet paraat heeft om het weer te geven (is bij mij bijvoorbeeld het geval voor Tagbanwa): dan krijg je blokjes en vraagtekentjes. Kan omzeild worden met alternatief ophakken van je boodschap, of door een font te installeren dat met Tagbanwa overweg kan.
O ja, en sommige schriften lopen van rechts naar links. Kan ook mogelijk roet in de soep gooien.
Dus, het is allemaal een beetje passen en meten en persen, maar het concept werkt en daar gaat het maar om ja toch niet dan.
Voorbeeldtekstje
Een gedichtje van Kees Torn in Unicodecode:
Mijn neefje, waar ik eerst mee Pimpampette,
al volgde hij de regels niet precies,
was eerlijker bij Russische roulette,
alleen, hij kon niet tegen zijn verlies
㔪㭮ᒦ⢽满ٛ╻ᒲ些㒥䄭䀭䂴傽
֛ 姬ä»K沅湅Წ佮⒴渒ᑩᙽ
尳沥䦉⥥䭢╛䪳䴳䱨»䧵ゴ傽
,ゥ㮨╛ů㭮⒴傧ᗛ椪㭶ᙌ⒳
U ziet, het levert behoorlijk vaak Chinese/Japanse/Koreaanse tekens op, maar ja, daar zijn er nu eenmaal ook disproportioneel veel van, dus dan krijg je dat.
Voor wie zelf wil proberen
Zelf aan de Uniknutsel? Download de omzettabel (.xlsx) hier.
Of nog beter
Een regelrechte app, verzorgd door Jan van Straaten!